Hey all. I've been wondering how far I can push my ink cartridges. I'm using HP Latex 310, and the cartridges are 775 ml. I was told by my sales rep to replace inks as soon as the machine says they're low, which usually happens around 100ml. This seems kind of insane to replace such a huge cartridge with 1/8 of the product left in it. Then again, I'm not an expert, and I don't want to end up ruining printheads or getting air in the lines. Does anyone else using HP Latex have advice? How low do you let your inks get before replacing them?
-
I want to thank all the members that have upgraded your accounts. I truly appreciate your support of the site monetarily. Supporting the site keeps this site up and running as a lot of work daily goes on behind the scenes. Click to Support Signs101 ...
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
How Low Do You Let Your Inks Get?
- Thread starter SCDesign
- Start date
iPrintStuff
Prints stuff
I know pretty much every ink on the market generally has more than stated on the packet, so you can run them to “0” and they still have some left, for the specific reason of not letting air in the lines etc.
I don’t have a HP but to me, leaving 1/8 of the ink in every cartridge seems a bit crazy! I’d definitely leave that in a lot longer.
I don’t have a HP but to me, leaving 1/8 of the ink in every cartridge seems a bit crazy! I’d definitely leave that in a lot longer.
iPrintStuff
Prints stuff
For our Colorado I always keep approx 2 days worth of full printing - and we get inks in next day, the two days is just a precaution.
The UV inks last about 1 year from the date we get them, but they usually don’t usually stick around long lol.
how long to the HP inks last before expiring?
The UV inks last about 1 year from the date we get them, but they usually don’t usually stick around long lol.
how long to the HP inks last before expiring?
P Wagner
--
Many users of HP Latex printers drive the cartridges completely empty. When an ink color goes to 0, the user has about 30 minutes to replace the ink cartridge and the job will pick up and continue, in the vast majority of cases without any visible defects. If the inks are not replaced within about 30 minutes the job will be cancelled.
It is important to begin the cartridge replacement at the printer front panel, as the ink delivery system is pressurized on HP Latex printers.
It is important to begin the cartridge replacement at the printer front panel, as the ink delivery system is pressurized on HP Latex printers.
Last edited:
Bradley Signs
Bradley Signs
Of course they want you to get new ones when it sez your low! How do you think they make their money? Buy selling more ink!
Solventinkjet
DIY Printer Fixing Guide
Do HPs not have an ink end sensor?
P Wagner
--
Do HPs not have an ink end sensor?
Yes, there are electronic ink sensors for each ink channel, located at the cartridge interface. Monitoring things like ink levels (as well as the amount of media remaining on the roll) can be done at the printer front panel, remotely on the computers on the local area network, or even more remotely through a smartphone app to deliver true mobility (see attached).
Attachments
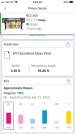
Solventinkjet
DIY Printer Fixing Guide
Yes, there are electronic ink sensors for each ink channel, located at the cartridge interface. Monitoring things like ink levels (as well as the amount of media remaining on the roll) can be done at the printer front panel, remotely on the computers on the local area network, or even more remotely through a smartphone app to deliver true mobility (see attached).
Ok good! I couldn't believe what I was reading!
chrisphilipps
Merchant Member
You should be good to use it till it says that it is empty. I personally haven't had any issues doing this on our demo units and customer haven't had issues either. The printer pressurizes the cartridge and reads the pressure on the ink system to detect how much ink is left.
One word of warning is when the bag gets towards the end it isn't all that accurate on the display in regards to how much is remaining. It is always a good idea to have a backup on hand before they get below the 100ml mark. It isn't uncommon for it to drop about 20ml without warning as it rechecks the pressure on the cartridge.
One word of warning is when the bag gets towards the end it isn't all that accurate on the display in regards to how much is remaining. It is always a good idea to have a backup on hand before they get below the 100ml mark. It isn't uncommon for it to drop about 20ml without warning as it rechecks the pressure on the cartridge.
Question for you... Very rarely has it happened, but I can think of twice now when I let it run to 0, and it ends up killing the head. Usually on the light heads, or magenta... I just had a head that was just swapped and working fine... It had about 130 ML through it, the ink ran out...I put a new one in and the head was completely dead, no ink running through it at all. I tried a few cleanings and nothing... I did a nozzle drop test and all nozzles were gone. I put a new head in and it worked perfectly fine.Yes, there are electronic ink sensors for each ink channel, located at the cartridge interface. Monitoring things like ink levels (as well as the amount of media remaining on the roll) can be done at the printer front panel, remotely on the computers on the local area network, or even more remotely through a smartphone app to deliver true mobility (see attached).
I just had it happen a week ago actually, it's been sitting on my machine waiting for me to RMA it...
 Just been too busy. Just wondering if this was a common thing, or if theres some other option I can do to recover the heads? 9.9/10 times its not an issue, just the odd occurrence that it kills a head.... which isnt a big deal since as long as its under warranty, it just means I get a new free head
Just been too busy. Just wondering if this was a common thing, or if theres some other option I can do to recover the heads? 9.9/10 times its not an issue, just the odd occurrence that it kills a head.... which isnt a big deal since as long as its under warranty, it just means I get a new free headgreysquirrel
New Member
run it until the printer tees you its empty...run your heads until IQ is no longer acceptable...
Print1
Tech for your cutter, printer & logistics needs
You don’t have to replace as soon as it tells you too, however it’s shortly afterwards, once it starts sucking air you’ll be In for a lot of head purges. I’d say though you’ll want to run maybe 5% longer but that’s marginal. My Vutek I could run to 2% but those are very much different monstersHey all. I've been wondering how far I can push my ink cartridges. I'm using HP Latex 310, and the cartridges are 775 ml. I was told by my sales rep to replace inks as soon as the machine says they're low, which usually happens around 100ml. This seems kind of insane to replace such a huge cartridge with 1/8 of the product left in it. Then again, I'm not an expert, and I don't want to end up ruining printheads or getting air in the lines. Does anyone else using HP Latex have advice? How low do you let your inks get before replacing them?
balstestrat
Problem Solver
On HP the ink pouches should have zero air inside them so it can not suck air. Also those 775ml have no ink pump either. The ink is just being pushed out of the pouch. Imagine like trying to empty a small bag of ketchup. It will see that it's empty when no ink is moving anymore.You don’t have to replace as soon as it tells you too, however it’s shortly afterwards, once it starts sucking air you’ll be In for a lot of head purges. I’d say though you’ll want to run maybe 5% longer but that’s marginal. My Vutek I could run to 2% but those are very much different monsters
Even with the big latex 10Liter bags you can go all the way to zero.
Print1
Tech for your cutter, printer & logistics needs
Until it reaches max negative pressure. Then there is a pressure Valve that will release to avoid blowing out the head. Obviously more extreme but it can happen. Usually the chip will run out before that though.On HP the ink pouches should have zero air inside them so it can not suck air. Also those 775ml have no ink pump either. The ink is just being pushed out of the pouch. Imagine like trying to empty a small bag of ketchup. It will see that it's empty when no ink is moving anymore.
Even with the big latex 10Liter bags you can go all the way to zero.
balstestrat
Problem Solver
No the air pressure to push is constant, its not changing. The bag is just simply considered empty when its as empty as it gets with the normal pressure. There won't be negative pressure because there is no ink pump.Until it reaches max negative pressure. Then there is a pressure Valve that will release to avoid blowing out the head. Obviously more extreme but it can happen. Usually the chip will run out before that though.
So actually when you are running empty there is no way to explode your head because you have no ink you can not generate pressure in the ink line.
Do not run your inks to 0.
I am very cautious about this and at 10% I run the replace Ink menu and pull the cartridge , then gently rock it. if it has ink you can feel it.
If you can not detect ink in the cartridge, Replace it!
If you detect ink you should know if that will be enough ink for the next job.
30 ml is pretty much low as I will go.
Now for the Scalding.
Replace at 30- 40 ml. If you are trying to squeeze it down to 1% then
you are pinching the wrong Pennies.
You are paying $135 for a cartridge. Why you so Cheap?
HP 9000 and Seiko Color Painter inks ran $240 - $280 for a 1L Cart.
Then you had the wiper blades and solvents and, etc. etc. etc.
These were very expensive printers to run and maintain.
I am very cautious about this and at 10% I run the replace Ink menu and pull the cartridge , then gently rock it. if it has ink you can feel it.
If you can not detect ink in the cartridge, Replace it!
If you detect ink you should know if that will be enough ink for the next job.
30 ml is pretty much low as I will go.
Now for the Scalding.
Replace at 30- 40 ml. If you are trying to squeeze it down to 1% then
you are pinching the wrong Pennies.
You are paying $135 for a cartridge. Why you so Cheap?
HP 9000 and Seiko Color Painter inks ran $240 - $280 for a 1L Cart.
Then you had the wiper blades and solvents and, etc. etc. etc.
These were very expensive printers to run and maintain.
BluetailGFX
Journeyman
I tend to kick them out of the HP after they hit below 50ml. Had a couple instances like others have mentioned, letting it go to 0, and having a quality print issue or the head totally dies prematurely. I do keep some of the cartridges and will swap them back in for short runs to use up as much as possible. But no matter what, there is going to be solid debris in the last bits of any ink cartridge. Why test their quality control and risk your own production schedule for just a few pennies?
AGCharlotte
New Member
run them dry... if I'm not going to be near the machine or letting something run overnight I'll swap it til I get back. If it runs out mid-job, it'll make a fuss and you've got 15 min or so to swap the ink before it aborts the job (someone else said 30... so I'm not certain on the timeout).